Audio Samples
Music Mixing Style Transfer with realworld recordings.
We perform style transfer using MixFXcloner trained with Φp.s. on realworld recordings. Our system converts the mixing style with stems separated by Hybrid Demucs.
We perform style transfer using MixFXcloner trained with Φp.s. on realworld recordings. Our system converts the mixing style with stems separated by Hybrid Demucs.
Please use devices such as speakers, headphones, and earphones in a quiet environment to analyze the sound source.
| Sample Index |
Song A | Song B | Style Transfer |
Converted Output | |
|---|---|---|---|---|---|
| #1 | "Young Lust" by Pink Floyd | → | "If You're Too Shy" by The 1975 | A→B | |
| ← | B→A | ||||
| #2 | "Everything Goes On" by Porter Robinson | → | "I'm in Love With You" by The 1975 | A→B | |
| ← | B→A |
Results of Music Mixing Style Transfer from the proposed models.
We compare the outputs from MixFXcloners trained with different audio effects encoders. Samples of Target Style Mix (ref) and Ground Truth (gt) in this section were generated using our FXmanipulator.
We compare the outputs from MixFXcloners trained with different audio effects encoders. Samples of Target Style Mix (ref) and Ground Truth (gt) in this section were generated using our FXmanipulator.
Please use devices such as speakers, headphones, and earphones in a quiet environment to analyze the sound source.
| Conversion Type |
Sample Index |
Initial Mix (x) |
Target Style Mix (ref) |
MixFXcloner w/ MEE |
MixFXcloner w/ Φ∅ |
MixFXcloner w/ Φnorm |
MixFXcloner w/ Φp.s. |
Ground Truth (gt) |
|---|---|---|---|---|---|---|---|---|
| Multitrack conversion |
#1 | |||||||
| #2 | ||||||||
| #3 | ||||||||
| #4 | ||||||||
| Single stem conversion |
drums | |||||||
| bass | ||||||||
| vocals | ||||||||
| other |
Comparison with DeepAFx-ST. which shares a very similar task: style transfer of audio effects.
Our system converts the mixing style with stems separated by Hybrid Demucs.
Our system converts the mixing style with stems separated by Hybrid Demucs.
Note that this is not a fair comparison since DeepAFx-ST converts the EQ and compression style as a mixture level, while MixFXcloner performs stem-wise conversion on the general mixing style.
| Style | Input | Reference | DeepAFx-ST | MixFXcloner |
|---|---|---|---|---|
| Neutral to Warm | ||||
| Telephone to Neutral | ||||
| Bright to Broadcast |
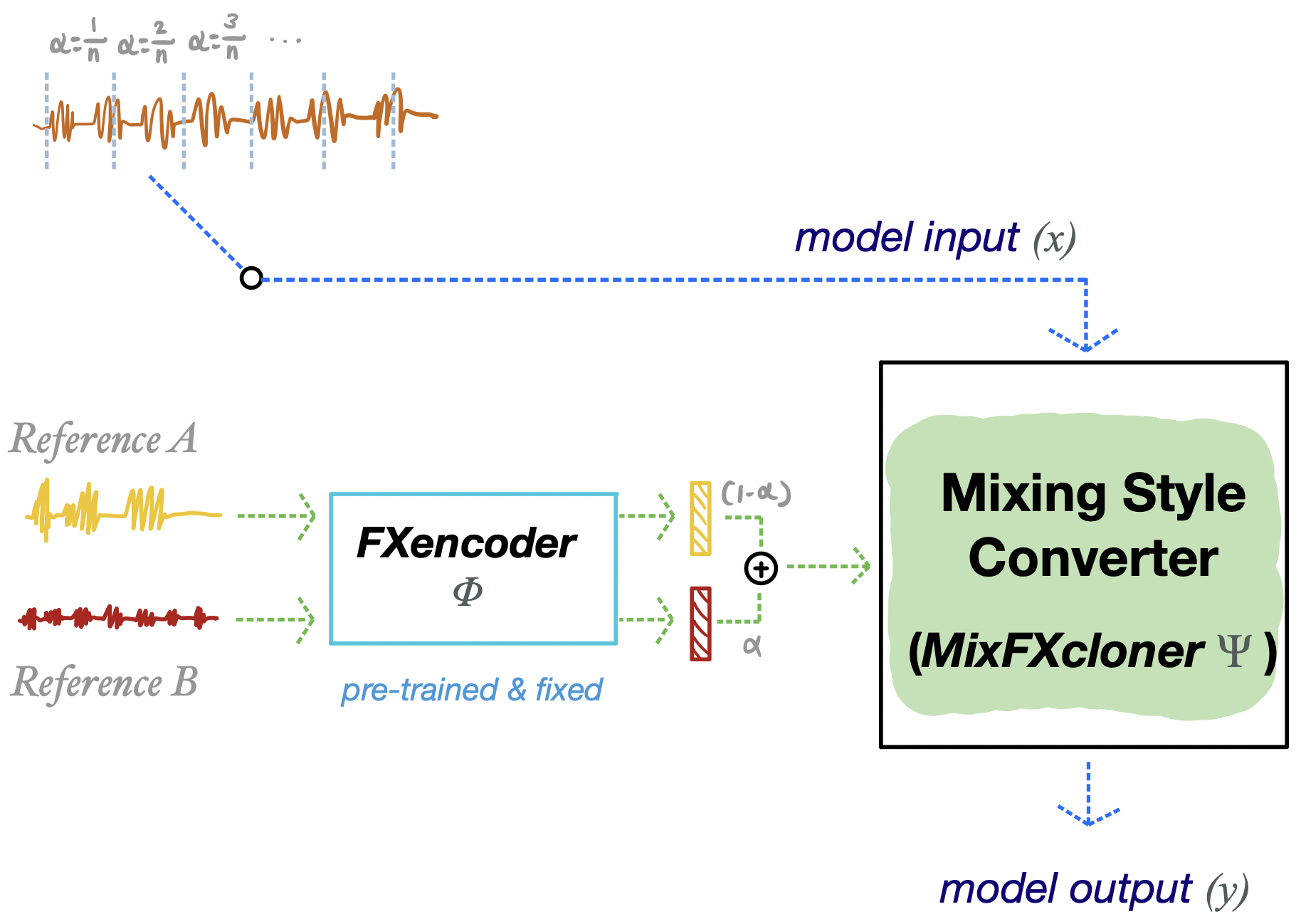
Interpolating 2 different reference tracks.
We encode two different reference tracks then linearly interpolate those two embeddings for inference. This example segmentizes the input into 30 pieces (approximately 1 sec. per each segment) then condition the linearly interpolated embeddings that is weighted from Reference A to Reference B
We encode two different reference tracks then linearly interpolate those two embeddings for inference. This example segmentizes the input into 30 pieces (approximately 1 sec. per each segment) then condition the linearly interpolated embeddings that is weighted from Reference A to Reference B
This demonstration is not mentioned in the paper, but this example implies a potential for controllable style transfer using latent space.
| Input: | Reference A | → | Reference B |
|---|---|---|---|
| Target Style Mix | - | ||
| Interpolation Output | |||
| Individual Output | - | ||
Methodology
System Overview
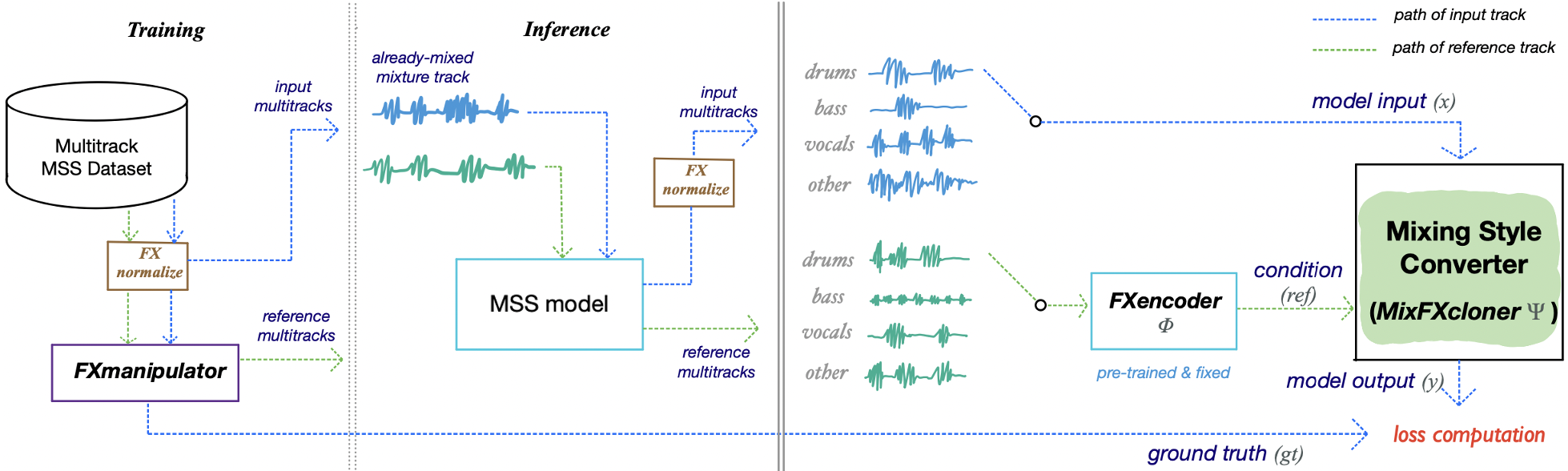
MixFXcloner Ψ aims to convert the mixing style of the input track
to that of the reference track. This is assisted by FXencoder Φ which was pre-trained with a contrastive objective to encode only the audio
effects-related information of the given audio track. During the training stage, we randomly select two different segments of each instrument
track from the Music Source Separation (MSS) dataset then FX normalize them. We input one of the chosen segments to the MixFXcloner,
where its objective is to match the mixing style of the other track manipulated by the FXmanipulator. We apply the same manipulation to
the input to produce a ground truth sample for loss computation. During the inference stage, not only we can transfer the mixing style of
single-stem inputs, but also mixture-wise inputs by using a MSS model.
Training Procedure of the Audio Effects Encoder (FXencoder)
The main idea of the Audio Effects Encoder (FXencoder) Φ is to disentangle FX information from music recordings.
We adopt a contrastive learning approach to solely discriminate the difference of FX among various mixing styles.
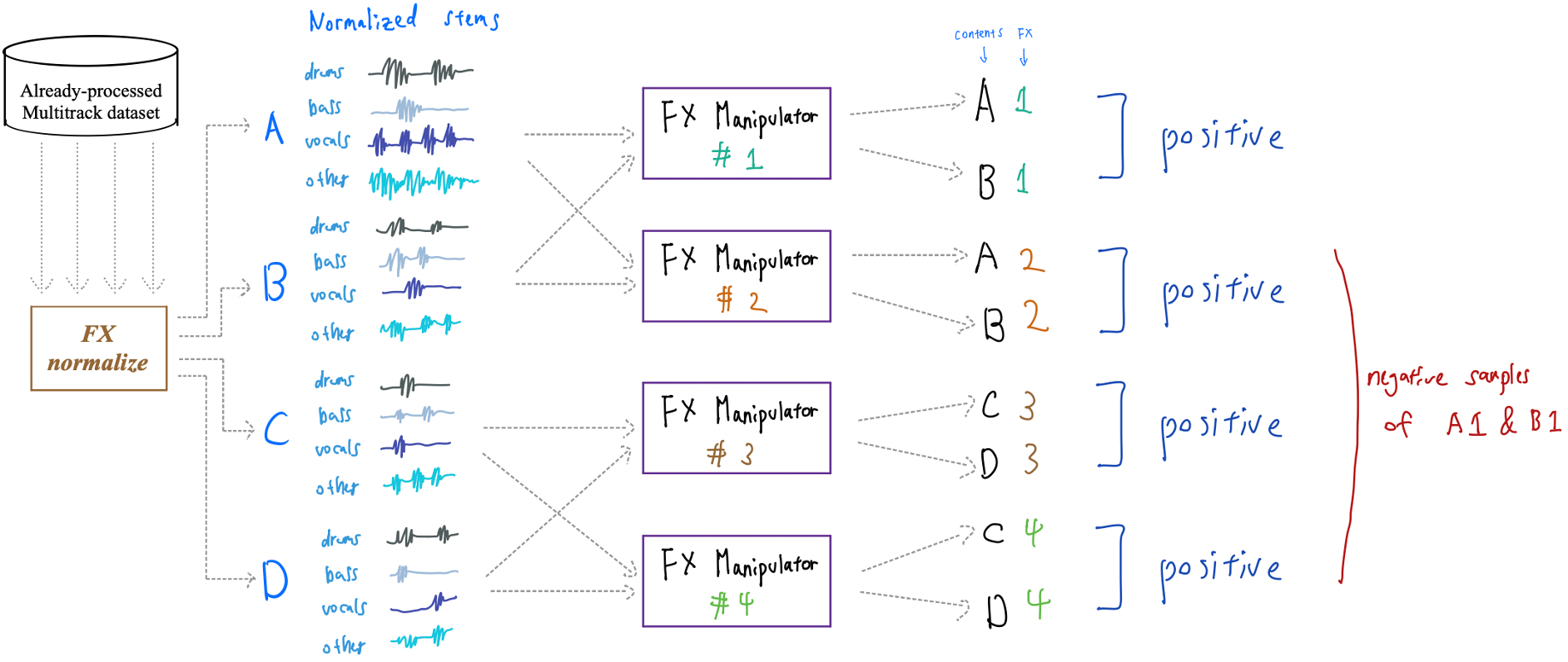
Training Procedure:
1. preprocess the input data with FX normalization to normalize features related to audio effects
2. apply the same manipulation using FXmanipulator to two different contents and assign them as positive pairs
3. a batch of manipulated tracks is formed by repeating this procedure, where contents applied with different manipulations are assigned as negative samples
2. apply the same manipulation using FXmanipulator to two different contents and assign them as positive pairs
3. a batch of manipulated tracks is formed by repeating this procedure, where contents applied with different manipulations are assigned as negative samples
EVALUATION
This work mainly assesses FXencoder with its effectiveness in extracting FX from a music recording and how informative the encoded representation is to performing mixing style transfer.
Disentangled Representation of the FXencoder
Qualitative Evaluation

Points with the same color represent segments of different songs manipulated with the same FXmanipulator parameters. Therefore, each color group contains the same 25 songs.
From (a)~(d), we observe that our proposed FXencoder forms better clusters than the Music Effects Encoder (MEE) according to each group of audio effects.
(e)~(h) demonstrates the importance of our proposed probability scheduling, where the encoder trained with this technique is better at clustering upon less dominant audio effects.
From (a)~(d), we observe that our proposed FXencoder forms better clusters than the Music Effects Encoder (MEE) according to each group of audio effects.
(e)~(h) demonstrates the importance of our proposed probability scheduling, where the encoder trained with this technique is better at clustering upon less dominant audio effects.
Objective Evaluation

We quantitatively measure the representation of FXencoder using metrics that convey disentanglement information.
This table summarizes disentanglement performance on representation obtained from combinations of multiple/single audio effects applied on multitrack/single stem.
Mixing Style Transfer
Objective Evaluation
Overall, we observe the tendency of each model's performance to be the same as observed in Disentangled Representation of the FXencoder.
Moreover, we evaluate our system upon the inference pipeline using a MSS model. The mean SDR value between the original and source separated outputs are 8.004 and 4.554 for mixture and stem-wise conversion, respectively. The higher SDR for the mixture could be due to the fact that the artifacts caused from the MSS model get cancelled out on mixture level conversion.
Moreover, we evaluate our system upon the inference pipeline using a MSS model. The mean SDR value between the original and source separated outputs are 8.004 and 4.554 for mixture and stem-wise conversion, respectively. The higher SDR for the mixture could be due to the fact that the artifacts caused from the MSS model get cancelled out on mixture level conversion.
Subjective Evaluation
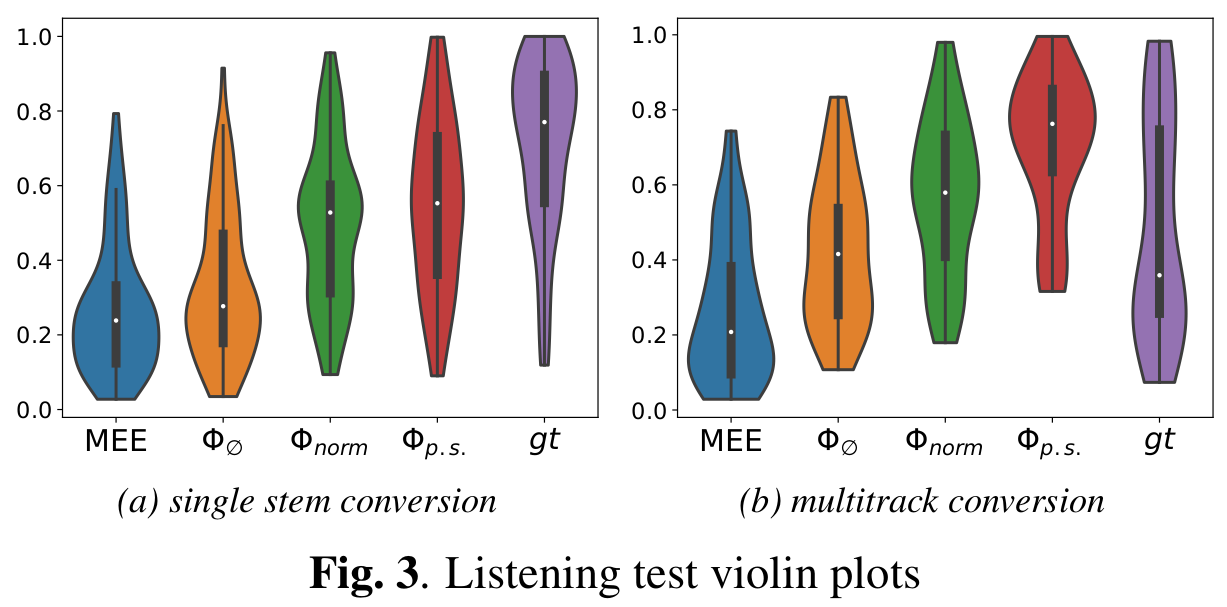
A total of 11 audio engineers participated the listening test, where the participants were asked to rate different mixes based on their similarity to the reference mix in terms of audio effects characteristics and mixing style.
For both the single stem and multitrack conversion, MixFXcloner using Φp.s ourperforms all other methods. Overall, similar performance was observed compared to the objective metrics.
For both the single stem and multitrack conversion, MixFXcloner using Φp.s ourperforms all other methods. Overall, similar performance was observed compared to the objective metrics.
SUPPLEMENTARY MATERIALS
We disclose detailed explanation, configuration, and full results of the paper at our supplementary materials link.
full results of t-SNE analysis
details of FXmanipulator
probability scheduling
listening test